内核篇¶
LinuxKernel¶
与main函数的区别就在需要链接的地方不一样,至少开头是静态链接的,对用initrd 之类的都采用两次load法,起动之前一次,起动后更新。 为了解决鸡生蛋,蛋生鸡的问题。同时对模块的热加载功能,insmode,rmmode,其实本质就是dllexport的功能。只是内核支持动态加载,而一般的应用程序做不到,只能通过gdb来这样么做。但是unreal 是能够做到一点。做到热加载的,编译之后直接可以用,不需要重起。
https://onedrive.live.com/edit.aspx/%e6%96%87%e6%a1%a3/GW%20%e7%9a%84%e7%ac%94%e8%ae%b0%e6%9c%ac?cid=0620a0b4441149e5&id=documents&wd=target%28%E5%BF%AB%E9%80%9F%E7%AC%94%E8%AE%B0.one%7C38E3E883-E41F-4858-BFB1-0BD8ED9EC575%2F%E4%B8%89%E8%A8%80%E4%B8%A4%E8%AF%AD%E8%81%8AKernel%EF%BC%9A%E4%BB%8ELinux%E5%88%B0FreeBSD%20-%20One%20Man%27s%20Yammer%7C80CCE1E5-1CD0-4CFE-979A-1832E55AAA29%2F%29 onenote:https://d.docs.live.net/0620a0b4441149e5/文档/GW%20的笔记本/快速笔记.one#三言两语聊Kernel:从Linux到FreeBSD%20-%20One%20Man’s%20Yammer§ion-id={38E3E883-E41F-4858-BFB1-0BD8ED9EC575}&page-id={80CCE1E5-1CD0-4CFE-979A-1832E55AAA29}&end
对于linux 整体的理解在上面写的很到位。 内容启动顺序是何定义的,根据优先级,同一优先级是根据链接顺序来的。而FreeBSD 则是SYSINIT固定的。
IO
每一种外设都是通过读写设备上的寄存器来进行的,寄存器又分为:控制寄存器,状态寄存器,数据寄存器。
从Linux2.4以后,全部进程使用同一个TSS,2.4以后不再使用硬切换,而是使用软切换,寄存器不再保存在TSS中了,而是保存在task->thread中 <http://blog.csdn.net/shinesi/article/details/1933851>`_ 一个线程就对应一个LDT的一项,内核是对物理硬件所做的一层抽象。而进程则是对CPU+内存+硬盘一种抽象。而线程则是对CPU的一种抽象。 linux 采用二级页表机制,页表目录和页表+页内基址。 Page=4K.
其实一个本质问题在于,如何这样的解读内存结构,这个与包的结构是一样的,是采用TLK的模式还是表头然后内容的方式。首先是分配大小。然后要根据自定义的结构来读写内存。类的内存结构与包的结构是一样的道理。
进程与程序的关系¶
<img src=”%ATTACHURLPATH%/C_memory.jpg” alt=”C_memory.jpg” width=‘600’ height=‘450’ align=right />
- C语言到汇编到机器语言到进程转换
- 从内存中加载并启动一个exe
- 可执行程序加载到内存的过程 第一步就是把文件用`mmap <http://blog.chinaunix.net/uid-26669729-id-3077015.html>`_ 映射到内存中。哪些库是放在共享区,可以供所有程序去调用,或者还是用到的时候才去加载。 Linux下程序的加载、运行和终止流程
- 程序的内存分配 只要看到thread_struct结构,它的那些寄存器值的大小限制。
- linux内核堆栈 是全局数据构使用的
- GDT与LDT的关系
进程数取决于GDT数据组的大小,线程的最大数取决于该系统的可用虚拟内存的大小。默认每个线程最多可拥有至多1MB大小的栈的空间。所以至多可创建2028个线程。如果减少默认堆栈的大小则可以创建更多的线程。
自己学习单片机的时候,就存在一个迷惑,那些操作单片机的小片子如何来支持一个操作系统一样的东西。现在逐渐明白了,其实如何让更多的程序能在计算机跑起来。所谓的空闲,其实CPU一直没有闲着,CPU采用的心忙状态。除非CPU的所有调度都采用中断实现。单片机的存储机制只有两层,那就是寄存器与内存。CPU的操作是不能直接操作内存地址进行运行的,而是要把内容加载到自己的寄存器然后再进行计算,然后再把数据写给回去。现在CPU架构采用是统一地址,这样的话,地址就要分段了,哪些地址是可读的,哪些地址可写的。CPU执行原来就是依赖其那些寄存器。` 在此 <http://os.51cto.com/art/201005/199799.htm>`_ linux采用了内核地址与用户空间地址的做法,例如内核地址3G-4G这一段地址留取了内核来用,0-3G这段刘给了用户,用户之间隔离的,内核地址空间是共享的,这里有一个偏移量的问题,更好是3G,把内核地址减3G正好是从头开始,而用户空间从+3G就变成真实空间了。其实一个进程都是对CPU的运算结构进行了抽象,并且对CPU做了两级的抽象,那就是线程。然后由内核把每个程序相关的资源都放在一个进程结构里,一个每个进程就是GDT里的一项。即是哪一段内存给它用。记录与它相关于文件等等,然后按照CPU的结构把寄存器初始化,执行,保存结果然后再换出。每一个进程头是放在GDT中,所以去查看GDT表就以操作当前有多少进行在运行。LDT对应的是线程。一般线程只有代码执行区与寄存器的运行状态记录,而所有资源都是放在进程里。
进程的内存功能分块
- 代码区,主要用来存储二制代码
- 数据区 用于存放全局变量
- 堆区,动态的进行内存的分配与回收。
- 栈区,主要存储函数的参数以及返回地址等目的被 调用函数执行完毕后能够准确的返回到冷饮函数继续执行。
所以一个进程如右图那分了,3G-4G的那部分地址给内核的,自己的代码区还要占据一定的空间,另外一些全局的数据空间,以及堆栈的地址空间,最后还是自由的地址空间。所以在同一个框架下,一般程序的入口地址都是相同的。然后就把程序初始地址分给CP寄存器。到底指令要占多少呢,也就是我可执行程序有多大呢,这个就要你的`指令的长度 <http://www.mouseos.com/x64/puzzle01.html>`_ 再乘以指令数就是所要占的内存大小了. 当然只要这些计算机就能识别了。但是对于我们人来说有点难懂了。那好吧,再把符号表给加上。这里的`符号表 <http://zh.wikipedia.org/wiki/%E7%AC%A6%E5%8F%B7%E8%A1%A8>`_ 来记录各种人为可读的标记。然而如何把C语言与汇编语言关联起的。是翻译的过程中如何会记录这些值的呢。
地址的长度其中之一的功能,那就是寻扯空间变大了,这样的代码就可以更长了。例如8位机,如何顺序代码超过了其寻址能力的话,就无法实施了。就限制了其功能。
现在回头把操作系统又看了一遍,原来进程是为了并行计算而产生的。解决了原来的只能顺序执行的问题。这样就有了数据段,程序段,进程控制块。这样进程其实就是对CPU结构以及计算机的存储单元的一种抽象。同时操作系统系统与进程的接口,就是这些信号。所在在链接时,所谓的链接器,是由内核来调用加载进程。信号是一种软中断。每一个进程对每一个信号都有一个默认的处理方式。操作系统也占用了几个。同时我们可以进程进行各种操作。通过信号。
对于内存地址的真实分配可以从 dmesg里看到 VirtualKernel memory layout,也可以从 /proc/ http://unix.stackexchange.com/questions/5124/what-does-the-virtual-kernel-memory-layout-in-dmesg-imply
一个kernel的内核也没有多大,也就几M大小,可以 ll -h /boot 就可以看到它的大小。 只是添加内存的分配与dll的扩展功能。一供也才不超过6M大小。一个指令4个字节。也就不超过 6M/4=1572864 条指令,最多需要1.5M地址就够了。 而8位的只能256条指令,16位也只64K的地址长度,32位 就有了4G的地址。 所以在32位上我们停留很长时间,因为我们32位对于我们来说,已经远远大于逻辑指令了。只所以要让上升64位,主要是数据空间的不足。而到了64位地址长度基本上就目前需求就相当于无穷大了,也很巧的周易也只推演到了64卦就停止了。
- 代码混淆器 也提供了一种代码互相翻译的功能。
安全策略¶
linux 的内核支持 security module的支持,你可以加添加各种安全模块,以及定义安全策略,例如selinux,
进程管理¶
以前是单核分时复用机制,只用考虑时间的分配,而现在出现了真正的多核与多线程机制。实时性的问题也就解决了很多。同时对于调度也有很大的区别。例如如果让进程在多个核上切换,而上车与下车都是要overhead,如何使减少。这个很重要。
出现这个sched_yield, 这个API是为了提高效率,当发现自己被blocking了,就CPU的运行权交出去。以前的进程比较难控制自己的执行。 http://blog.csdn.net/magod/article/details/7265555
multi-process and multiple thread until now, I find how to use the fork, why we need the fork? when the fork the children copy the code,data from parent process. and then do their own things. the questions of article is good, help me think. you can reference here why need multiple process.
可以用chrt 来控制进程的调度,或者合用sysctl来进行控制。sysctl -A|grep "sched" | grep -v "domain"
cputopology
多核CPU拓扑, https://www.kernel.org/doc/Documentation/cputopology.txt
http://www.ibm.com/developerworks/cn/linux/l-cn-sysfs/ /sys 是sysfs的挂载点,取代了/proc的大部分功能,并且经过了很好的设计。
当然也可以用 man /proc 与man sysfs来得到更多信息。
print "Started with the heartbeat host $HeartbeatHost:$HeartbeatPort\n";
if($ForkFlag)
{
if(fork())
{
exit(0);
}
close(STDIN);
close(STDOUT);
close(STDERR);
}
SetupSocket();
while(1)
{
SendHeartbeat();
sleep($SleepTime);
}
%ENDCOLOR%
system call¶
- Adding A System Call CUDA 应该就是这么干的,添加调用,这样它才知道东东传给GPU去做。
- Implement-Sys-Call-Linux-2.6-i386
brk,sbrk,getrlimit,setrlimit,prlimit查看系统资源的systemcall.
libc的库有一个gensyscalls.py 生成 syscall 例表。 /ndk/toolchains/X/prebuild/<platofrm>/share/lib/syscalls 可以看到各个系统的system call 个数,现在linux 325个API。
这些systemcall与大部分 shell 命令是对应的,例如mkdir等,其实本质就让shell 过程
while(1) {
switch {syscall} {
case ...: {do something};
}
}
其实内核就是一个数据结构,我们只是在不断的改其设备,就像 game Engine是一样的。
Signal¶
before, I always feel msterious about the signal. but now I know that the signal is always with us. for example, when shutdown, the OS should close all the process, how to do this, send the signal. the basic module of process with glibc should be able to the common signal. for example we use the kill -9 process to let the process close.
essentially, the Signal is relevent logic/soft interrupt with CPU and Hardware. 在ring 0改变watchpoint的值 continus received SIGTRAP.
for Debug, there are three way you can control.
- state register, this can control CPU behavoier.
- CPU event
- interrupt.
对于中断的处理,原则是要保存当前的所状态,中断处理之后,再恢复回来。 但是为了性能,而是根据需要来保存一些必要的register,而非全部。 而这些于profiling就会影响很大,因为它要用大量的信息,例如unwind callstack.
SystemLog 机制¶
多进程同写一个文件,就是会同步与原子操作问题。正常情况下,每一个系统调用都是原子操作。原子操作水平是什么样的。例子函数级的,还是指令级,还是API级的,中断CPU指令级,所以所有的单指令操作都是原子操作。同时原子操作都需要下一层的支持,在同一步不可有做到真正有效原子操作。就像第三方的中立性一样。这个就需要系统构构了,例如ARM的结构,并且内核的原子操作都是直接用汇编来锁定总线来搞定的,这个是C语言做不到的。
- Linux系统环境下关于多进程并发写同一个文件的讨论
- 多个进程把日志记录在同一个文件的问题 利用消息队列+单进程读写文件 会大大改善IO,但是多机并行的机制呢。
debug¶
内核中开发调试是最难的,简单是直接使用log,你如dmesg,以及在内核中打开更多的debug 选项,以及klogd,以及 在内核中打开远程调试来进行debug. http://www.embeddedlinux.org.cn/html/yingjianqudong/201303/12-2480.html 也可以采用类似于pdb的做法,动态调试直接在加入汇编指令来做。 http://blog.chinaunix.net/uid-20746260-id-3044842.html
module 本身也是 debug选项可以用的。 可以参看manual.
See also
- 浅析动态内存分配栈与堆 当数据量非常大时,使用什么策略来用内存。例如我们能同时对多少个数进行排序。
- linux sourcecode search
- /sysfs 文件系统类似于/proc 但是优于/proc
Thinking¶
你对linux哪一个熟 我是当linux当作一个仓库,遇到一些问题,是里面看看他都是如何实现的。然后结合自己的需求来实现。
– Main.GangweiLi - 02 Dec 2012
sysctl modifies kernel parameter at runtime
– Main.GangweiLi - 15 Apr 2013
现在对于linux的文件系统有了更加深切的认识: /usr/{include/src/lib) 这个里面放开发环境库 /usr/share/ 放了一些共享的信息例如man 等。 /lib/ 下面放的runtime lib
– Main.GangweiLi - 04 Nov 2013
对于环境变量 在操作系统内部进程之间的交互,很大一部分那就是还环境变量与配置文件,例如os.system如何知道系统有哪些环境变量呢,就是通过Path来知道的,所以如何才能加一条命令呢,那需要加入相应的path就可以,就可以让其os.system得到这条命令了。
– Main.GangweiLi - 17 Apr 2014
内存结构¶
内存模型 由最初的点线面关系问题,自己理解了内存是如何转化的过程。也就是知道一个矩阵如何在内存的问题。至于类与结构体,都是我们人对被处理对象进行的建模,其实就是向量。但是向量的里面的每个成员是不一样。例如哪些是变量,哪些函数。然后哪里数据区存放的地方,以及代码存放的地方。在C与C++中结构体与类都是从前往后按照先后顺序的。只要知道首地址,以及数据的长度,其实也就是TLV格式。数据的类型就是代表数据长度。起始地址是可以推算出来的。
内存地址的长度是根据CPU的地址线来决定的。 不同CPU的构架,内存框架结构也不一样的,一种UMA模式所有内存地址都一样,另一种那就是分类内存,其实本质两者都是一样的,如果把他们看成内存地址的话。[[http://wenku.baidu.com/view/0364850b763231126edb11a8.html][内存的分类笔记]] 并且现在明白内核映像只有512KB的原因,并且压缩格式的原因,是始于硬件本身初以状态下能够读入程序块有多大。不同的硬件,限制不一样。最小是512kb.例如硬盘的0磁道0磁头0扇区。只有512KB.
以前看龙书,有点看不动,现在再回头看龙书是那么一目了然。把内存管理那一张给看了之后,就全明白了,段页式管理是要解决两个问题。page swapping是为了解决内存不足的问题。而segment是为了解决了灵活性的问题。例如把代码改了,然后大小变了,所有地址都要重定向了。有了段之后,就把把影响变到最小,只用改段基址就可以了。就不用所有段重排了。进程结构是与CPU的物理结构相对应的。 并且现在CPU大部分都已经支持段了吧。这个就要看CPU的性能了。首先要了解需求。在解决什么问题。那个在面试的问的问题,就已经解决了,是因为它们没有段的结构,所以不能解决灵活性的问题,它们只是简单的页式吧。page是基于硬件的,segment是基于逻辑需求的。理解这些如何快速来得到使用这些就可以根据新需求与以及硬件功能来实现新的算法了。其实就是各个层面的排序与查找了。数组的高效以及链表的灵活。现在也明白了malloc的实现原理了,其实就是在改进程的data的首尾了。 page 的base为重定向,而limit是为了防止越界。
![digraph memoryStucture {
rankdir = LR;
node [shape = box ];
ZONE_DMA [ shape = record label = "<f0> 0-16MB | <f1> INIT address 0XFFFF0 BIOS |<IDT> Interrupt Table |<GDT> Global Descriptor Table |<LDT> Local Descriptor Table "];
ZONE_NORMAL [label = "16MB-896MB"];
ZONE_HIGHMEM [label = "896- END of Physical memory"];
MainLayout [ shape = "record" label = "<f0> ZONE_DMA |<f1> ZONE_NORML | <f2> ZONE_HIGHMEM "];
MainLayout:f0 -> ZONE_DMA:f0;
MainLayout:f1 -> ZONE_NORMAL;
MainLayout:f2 -> ZONE_HIGHMEM;
//IDT
IDT [shape =record label ="<f0> 256 Items 8bytes/item |{selector | keyword | offset }" ];
ZONE_DMA:IDT -> IDT:f0;
//GDT
GDT [shape = record label = "<des> 256 items |<f0> NULL | <f1> CODE Segment Descriptor| <f2> DATA Segment Descriptor |<f3> SYS Segment Descriptor | <f4> 252 for LDT and TSS for each TSS"];
ZONE_DMA:GDT -> GDT:f0;
//LDT
LDT [shape = record label ="<fes> 5 items | <f0> CODE segment | <f1> Data segment |<f2> BSS | <f3> Heap | <f4> stack"];
ZONE_DMA:LDT -> LDT:f0;
}](../_images/graphviz-09780819088db2131774dc5fee3b72cf1a6580ce.png)
#. [[http://guaniuzhijia.blog.163.com/blog/static/16547206920109914658702/][linux下进程的堆栈大小设置 ]] %IF{” ‘ulimit -a 可以查看所有’ = ‘’ ” then=”” else=”- “}%ulimit -a 可以查看所有 进程可以修改栈的大小,如果没有指定那么编译就是用默认的大小限制,linux 默认8M。
而如何查看这些东东呢。 linux采用的策略那就是能用我就尽量用,你需要用我就让给你。所以你会发现linux的buffer与cache会非常的大。
| command/file | content | remark |
|---|---|---|
| free | 查看系统的剩余内存 | |
| /proc/meminfo/ | 系统占用的内存 | |
| /proc/pid/maps | 进程占用的虚拟地址 | |
| /proc/pid/stam | 进程所占用的内存 | |
| /proc/kcore | kernel的大小 | |
| /etc/sysctl.conf | 来控制各种内存资源分配情况 | http://blog.csdn.net/leshami/article/details/8766256 |
| /etc/sysctl | 直接动态的去改内核的参数 | 并取代ulimit的接口 |
进程的内存分配¶
前1G之前是给内核用的,在gdb中通过info file 就可以看一个进程文件占用多大的空间。 在android, 它一般是从 0x400d0134=1G的地方开始的。 然后就是逐section,逐文件地进行加加载。 基本上都是 .interp->.dynsym->.dynstr->.hash->.rel.dyn->.rel.plt->.plt->.text->XXX->.rodata->.preinit_array->.init_array->fini_array->.data.rel.ro->.dynamic->.got>.bass
文件系统¶
介绍¶
文件系统是随着硬件的发展,以及数据存储发展的业务需要而不断向前发展的,并且两者之间的桥梁。
为充分利用内存空间,我们建立一系列的内存文件系统。随着数据量越来越大,我们也就需要分布式的文件系统。以及种备份的容灾的需求。
文件系统 ,任何时候不明白的都先回来看看最原始的教材。文件系统基本的功能,就是文件管理与目录管理。以及磁盘空间分配使用。 为什么要有这么多种文件系统。原因在于一定是不同的硬件实现。底层的实现是不样的。例如磁片硬件,与flash,以及固态硬盘,以及 人们对数据操作要求的不同。这种逻辑的需求与硬件结合的接口就是文件系统。对于不同的存储读写需求以及硬件实现,就会不同的实现实现算法机制。而这些就是文件系统。
对于硬件来说,对于磁盘片来说,那就是CHS。三级了。而对于flash也就又不一样了。 还是拿CHS模型来说,CHS最终还是定位到扇区上,每一个磁道的扇区数是不同的,最外圈的最大,最内圈的最小。每一个硬盘的参数表会有这些值的。 但是对CHS这种分区表方式会8G限制的问题,就有了后来的LBA模式,但是LBA模式最大支持2T限制。 CHS的MBR都是早期老掉牙方案了,虽然大部分讲分区原理都还在讲,但是拿这些理论已经不能解释现在的硬盘分区原理了,例如为什么现在分区是可以用GUID的。不过现在方案兼容老式的MBR。现在你看到的磁盘参数AAAA cylinders, BBBB Headers, CCCC sectors. 主要是为了让你换算LBA值来用的。LBA是绝对扇区号。换算方法是在这里`这里 <http://wenku.baidu.com/view/30e874c789eb172ded63b7c6.html>`_ . 而AAAA,BBBB,CCCC会做为硬盘参数的。 在往后会更大。这个主要是由于MBR机制造成的,因为MBR只留了64个字节给分区表。现在又出了一种新机制EFI方案中GPT表。这里 有详细的说明。
对应的逻辑设备分为族/块,卷/分区。对应的逻辑存储单位,如何把逻辑单位与物理单位对应起来,就是格式化的过程,在Windows里就是format, 在linux里就是mkfs这条命令的过程之一。系统之上操作都是基于逻辑单位操作的。例如现在是利用的位图来表示,一个位表示一个逻辑单位的空闲与否。同样大小的位图可以多少空间,取决于这个逻辑单位的大小。这个颗粒度的大小匹配你的存储对象的特点。而这些管理都是基于分区的,每一个分区内部肯定首先这些控制模块,还是这些控制模块是放在全局的。每一个最小单位chunk只能在一个文件里,两个文件不能共享同一个chunk.就是为什么你经常看到的,文件的大小与实际占用空间大小是不一样的原因,因为文件本身的大小不可能每次都正好是最小单位的整数倍。
对于管理还说还inode. 对于文件数据本身是可读可写,以及是否支持加密压缩等等。实现起来都是不一样的。每是每一个文件系统都能够提供的。并且还有。例如日志文件系统。对于文件的操作都是如何记录存储的。并且如何进行数据恢复。 常见的存储需求:本身是可读可写,以及是否支持加密压缩,数据恢复功能,读多还是写多,是大数据多还是小数据多等等。以及`性能的要求 <http://wenku.baidu.com/view/a8608606cc175527072208a7.html>`_ 。
为什么要分区呢,是为了管理上的方便,使之具有隔离性,例如装操作系统,就要在独立的分区上。等等。另外也取与操作系统有关心,硬盘的结构MBR. 启动信息与分区表都在这里放着,但是分区表只有64节节,第一个分区占16字节,这样一个分区可如果大于2*312*512=2TB时,这个分区表就不行了。这种物理结构决定了如何进行分区。GPT分区。EFI、UEFI、MBR、GPT技术 但是GPT模式在Windows上有很大的限制,那就是目录不能当启动盘。
而在抽象层上,就各种各样的文件系统。linux 文件系统设计的很好,在linux里一切的资源,要么是file,要么是进程。 debugfs,Pipefs,sockFS,securityfs 这些都是虚拟的文件系统。你可以在 /proc/filessystems 里看到这些。
而在linux中每一个进程空间只有一个根文件系统。 并且一个device都根据自身的结构形成自己文件系统结构。在异构系统之间,我们通过mount,来建立之间的不同系统之间通信桥梁。相当于在我的系统里,/xxx/XXX 就是你的入口点,往下的目录都是你的。即然是一个通信机制。就会信息通信协议,通信的方向是双方的,还是单方的。这也就有了四种
| private | shared | slave | unbindable |
具体可以说明见 kernel doc 应用挂载名称空间 来讲这些,空间的隔离,linux中使用各种各样的命名空间。
Pipe文件系统¶
linux 里大部分进程通信靠是Pipe,同步则是由Pipe 自己实现的,由于速度不的同,各种传输之间都会buffer来缓冲。 并且缓冲模式有
- buffered(默认4K), (STDin)
- unbuffred( 1byte)(STDERR)
- line buffered (1K) STDOUT
如果想控制这个buffer的大小,可以用stdbuf来调整。 可以查看man stdbuf.
http://blog.csdn.net/morphad/article/details/9219843 Pipe 文件系统的实现原理,pipefs 是虚拟的文件系统,使用用户空间的内存,挂载在内容中,并没有在根文件系统中。 用 kern_mount 来实现。
![digraph hardisk {
HardDisk [shape=MRecord, label =<
<table>
<tr>
<td>
<table><tr><td>MBR</td> <td>Partition Table</td> </tr></table>
</td>
<td>DBR </td>
<td>FAT </td>
<td>DIR </td>
<td>DATA </td>
</tr>
</table>
>];
}](../_images/graphviz-6ff6ced067fca20ac34af663d5fad0cf50698679.png)
| fdisk | Partition Table | |
| format/mkfs | DBR | |
| filesystem (inode ) | FAT | 这个是基于文件系统的 ,是不同的,主要inode的结构。 |
| ^ | DIR | |
| real data | DATA |
每一个分区的超级块放在这个分区的头,如果有就在第二个逻辑块里,一般情况下,第一块是引导块,第二块为super block并且大小固定。并且格式,大小固定。 超级块,采用的是相互链表,并且vfs做了很好的抽象,并且还支持cache,定期与硬盘同步数据。 http://guojing.me/linux-kernel-architecture/posts/super-block-object/
每一个分区的超级块是有备分的,你可以用mke2fs -n 或者dumpe2fs 来查看,然后再e2fsk -b 来进行修复。 http://www.cyberciti.biz/tips/understanding-unixlinux-filesystem-superblock.html
supperblock 中存储 文件系统的格式,inode/block的总数,以及使用量,剩余量等信息。 .block与 inode的大小(block 一般为1,2,4K,这些存储真实的数据,大文件可以用block,小文件可以的block, inode一般为124/256 byte). inode 存储的文件信息,例如文件属性,文件的权限,修改日期等等,文件名的链接,最后是文件数据block的地址。 http://www.voidcn.com/article/p-mttgftgp-gn.html
每一个分区四大块:
![digraph filesystem {
partition [ shape=Record, label="boot block|super block | inode index block | data block"]
}](../_images/graphviz-cd461dc83b8480a478b039de8ec5166ab453c47e.png)
并且这个根文件系统是在内存里。 可以通过chroot 来修系统 的根在哪里。这在很多地方都能用到,例如安装机制,例如 apache中,当然不能一般用户得以/etc/目录了,所以要把 apache中根目录要改掉才行。并且还可以其他目录拼接成一个新的目录。
例一个用法,那就是修复系统时可以用到,例如 https://wiki.gentoo.org/wiki/Handbook:AMD64/Installation/Base 把proc 从加载一下,
每一个进程的都会记录自己的根目录在哪里,这样才能解析绝对目录与相对路径。
- 硬盘知识,硬盘逻辑结构,硬盘MBR详解 64 字节的分区表
- ` Partition Tables <http://thestarman.pcministry.com/asm/mbr/PartTables.htm>`_
- INIX文件系统中,第一个块为引导块,第二个块为超块,之后的N个块是inode位图块(表示哪几个inode被使用了,总的inode个数由超块给出),紧接着是数据块位图,表示哪些数据块被使用了,紧接着就是inode块和数据块
- ext3 启动过程
- 硬盘及通用分区结构
使用sfdisk实现多操作系统引导 既然说到文件系统,就会主分区以及如何引导启动的问题。无非是在主引导区放了一个自己的引导管理器,来设置起动。而GTL的实现原理在于,用sfdisk来分区,把linux放在这个上面,并且如何保证始终在这个系统。目前看来,默认到都是先到这个操作系统,然后再由这个操作来用sdisk来改分区先项。但是如何来保证每一次都要改了启动选项呢。 其原理 是的windows 里使用LBOOT的原理就是利用GDisk 先改分区表,然后再起动。sfdisk 有一堆分区表,而MBR的分区表只表示当前活动的系统可见的分区。 一共有四个启动分区,其中一个常住了linux,并且在这个linux系统里放着sfdisk里的放着一堆分区表,然后系统活动的几个放在系统分区表。并且这个linux始终是第三个分区,所改变的前两项分区表。而Windows能够看到,就是把始动分区切到这个linux分区如果不需要切系统的就不需要了。然后linux再根据自己的分区表来更新系统的分区表。 所以sfdisk 需要一个第三方的东西来保存其分区表,在这里GTL用了第三个分区自身,并且在sfdisk里的一个参数 -o file 就是那个分区表的位置。
分区表除了要表示,分区的大小(通过起点,终点/长度来表示). 还需要分区的状态(活动与否),分区的类型也主要是用操作系统的类型。同一个值可能在不能操作系统下的识别是不一样的。MBR、分区表、CHS等概念 在DOS或Windows系统下,基本分区必须以柱面为单位划分(Sectors*Heads个扇区),如对于CHS为764/256/63的硬盘,分区的最小尺寸为256*63*512/1048576=7.875MB. 深入浅出硬盘分区表 分区表实际上一个单向的链表。
由于硬盘的第一个扇区已经被引导扇区占用,所以一般来说,硬盘的第一个磁道(0头0道)的其余62个扇区是不会被分区占用的。某些分区软件甚至将第一个柱面全部空出来。并且分区中就有一项,那就是第一个分区前面有多少个隐藏扇区。其实每个分区都会有一个引导扇区,也就是`VBR <http://en.wikipedia.org/wiki/Volume_boot_record>`_ ,整个硬盘的Boot record就是MBR。
现在明白了,老大的要讲故事,也就是要问为什么需要。同时也就是事情的前因后果,以及历史。自己如何早些问,那些文件系统有什么区别,现在也就早明白。直到现在才问。所以现在才明白。
| ext2 | http://learn.akae.cn/media/ch29s02.html | |||
| ntfs | http://bbs.intohard.com/thread-66957-1-1.html | http://blog.csdn.net/daidodo/article/details/2702648 | mount utfs as rw use fuse and ntfs-3g | |
| FAT | http://www.sjhf.net/document/fat/#4.3%20%20FAT%E8%A1%A8%E5%92%8C%E6%95%B0%E6%8D%AE%E7%9A%84%E5%AD%98%E5%82%A8%E5%8E%9F%E5%88%99 | |||
| rootfs | http://blog.21ic.com/user1/2216/archives/2006/25028.html | |||
| ramfs | rootfs | initrd and initramfs | http://hi.baidu.com/nuvtgbuqntbfgpq/item/537f1638797a88c01b9696f4 | |
| loop device /dev/loopXXX | http://www.groad.net/bbs/read.php?tid-2352.html | 把文件以及镜象挂载 | 是不是可以利用它来做系统血备份 |
看到现在终于把文件系统看懂一些吧,文件系统分为三层,文件本身内部结构一层,文件系统一层,分区与硬盘之间是一样。当然最初的概念都是结合物理模型的,随着后期的演化,最初的概念已经不是最初了的概念了。例如文件,最初都是就是一段扇区。但是到后期文件的已经完全脱离了,那个物理模型,就是变成了长度,并且这个常度就代表一个字节,并且字节也是一个抽象概念。不同的硬件,扇区的等等的分布是不一样的,不同的文件系统,block,inode之间对扇区对应关系都是不一样的。并且在文件系统上,文件不是顺序存储的。所以也就没有办法智能恢复了,也就只能整个硬盘做一个镜象,虽然你只用了一部分空间。 并且PBR的信息是放在分区里的,如果两个分区参数不一样,也是不行,相当于把分区的信息也复制过来了。而dd只能按块来读,在块之间来做转换。所以dd是在操作系统之下进行的,如果想用dd来做,要么两个分区一模一样,包括同样的位置有同样的坏道。要么要自己去解析文件系统的文件分配自己去读写分配每一个扇区。
文件系统格式¶
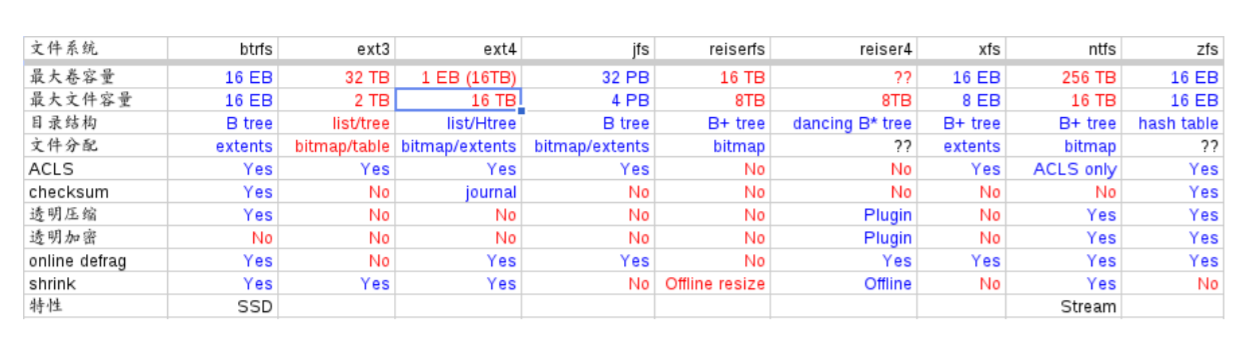
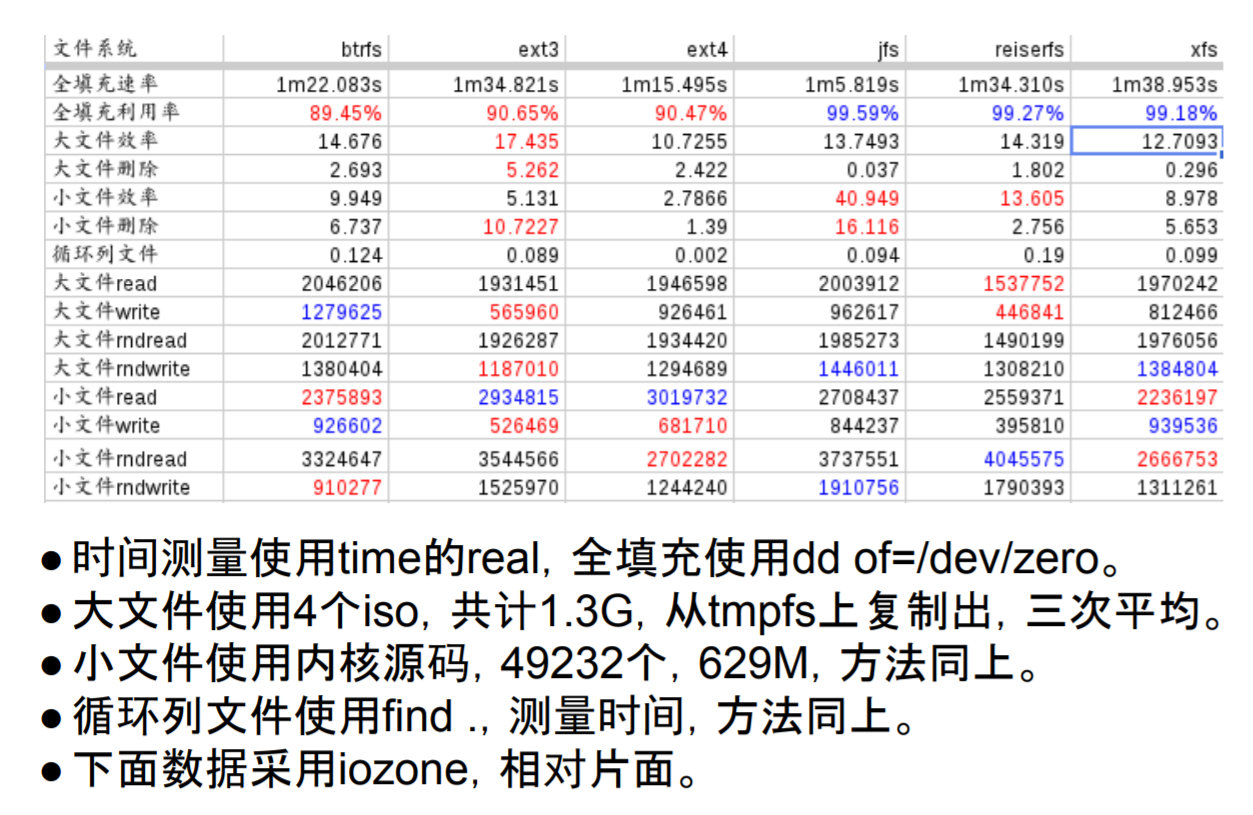
不同的文件系统格式,添加了不同的功能,特别是日志文件系统,添加一些数据恢复的功能,就像数据库可以根据日志rollback最佳状态。
https://zh.wikipedia.org/wiki/Ext4 增加了在线整理磁盘碎片的功能, ext3 是没有的https://zh.wikipedia.org/wiki/Ext3。 例如ext3grep,ext4magic, 大部分都是基于ext2fs_library.
http://extundelete.sourceforge.net/ 可以恢复数据ext2/3/4的数据。
下一代的文件系统 Btrfs 将是采用类似数据库的底层方式的B+ tree的文件系统。 进一步把文件系统与数据库融合在一起。
Btrfs 的简介 https://www.ibm.com/developerworks/cn/linux/l-cn-btrfs/index.htmloo 不同文件系统的性能分析 https://www.cnblogs.com/tommyli/p/3201047.html
android 主要是小文件,所以android系统默认是 ext4 格式。
调整分区的大小¶
http://blog.csdn.net/hongweigg/article/details/7197203
首先要自己记住分区的起始地址,然后修改分区表,然后再用 resize2fs,tune2fs 来更新文件系统的 meta data. 注意柱面号是按照unit 来计算的。 所以要学会计算这样。
如果想用dd来做, 先做一个OS,并且在硬盘上连续存放的,并且要知道这个区域的大小,或者说估计大约的值。并且硬盘状态一样。 这样可以像Copy文件一样,那样去做了。
另一个问题,分区的结构是否一样呢,如果分区的结构不样,例如索引节点的个数是不一样,这可能是按照分区的大小的百分比来进行的,如果新的分区足够大,就会出现浪费的问题,如果不够大就会可能出现错误。所以partitionclone最好的方式是能够认识文件系统。建立在文件系统上。就样可以解决这个问题了,这也就是为什么partclone要有那么多的,文件系统类型的支持。 可以直接使用 dd if=/dev/sda of=XXX.ISO 或者cat 直接做光盘镜象,然后直接使用mount来进行挂载。
dd if=XXX.iso of=/dev/<usbpartition> bs=4k cat XXX.iso > /dev/<usbpartition>
分区是对硬盘的一个抽象,对于OS来说,分区基本硬盘是一样的,并且分区上面还可以逻辑分区。block是对 扇区的一种抽象。文件相当于heads, 而目录相当于cylinders.
可以用 dumpe2fs 来查看文件系统,并且可以用 tune2fs 来调整参数。
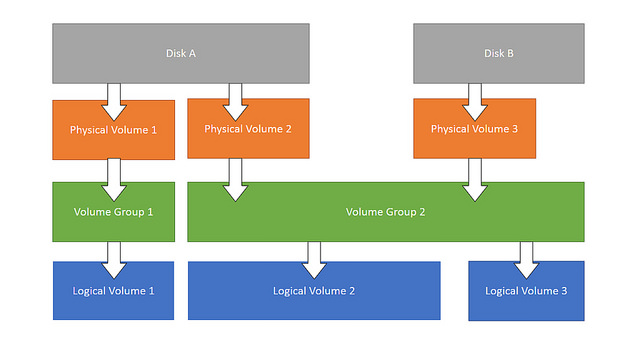
由于物理磁盘受限于空间的大小,扩展起来不是很方便,这就有了逻辑磁盘的概念。lvm. 先在物理磁盘上建立phiycal Volume, 多个PV 可以组成一个VG,然后在每一个VG上可以建立LV,当然LV可也可以扩VG。而LV就当做一个分区来用。并且随时能够调整大小。 pv,vg,lv.
partclone¶
partclone.ext3 -c -d -s /dev/hda1 -o hda1.img
cat sda1.ext3-ptcl-img.gz.a* | gunzip -c | partclone.ext3 -d -r -s - -o /dev/sda1
http://partclone.org/usage/partclone.php
ticons-1.0 --restore --filename:/mnt/work/safeos_work_dir/imgcache/A15690B1-70F2-4FA5-ADAF-D774FCB10336 --partition:1-1 --target_partition:1-1 --progress:on
partclone 对于ntfs 的支持比较有限,所以基本上还都是使用 ticons.
tree¶
用来查看filesystem的树型结构,并且通过用pattern过滤,以及控制输出各种格式XML,HTML以及–du 的功能。
Raid¶
- https://help.ubuntu.com/community/Installation/SoftwareRAID
- http://askubuntu.com/questions/526747/setting-up-raid-1-on-14-04-with-an-existing-drive
- https://raid.wiki.kernel.org/index.php/RAID_setup
- 七种raid配置通俗说明
原理是采用编码的冗余原理。但是数据量越来越大,传统的raid的对于数据恢复的需要的时候间也越来越长,因为也需要进一步raid上分片/分簇来局部化坏道与修复。
linux 采用 mdadm 来实现 /etc/mdadm.conf .
# mdadm -C /dev/md0 -a yes -l 5 -n 3 /dev/sd{b,c,d}1
mdadm: array /dev/md0 started.
-C :创建一个阵列,后跟阵列名称
-l :指定阵列的级别;
-n :指定阵列中活动devices的数目
[root@bogon ~]# mdadm --detail /dev/md0
/dev/md0:
Version : 0.90
Creation Time : Tue Mar 15 08:17:52 2011
Raid Level : raid5
Array Size : 9783296 (9.33 GiB 10.02 GB)
Used Dev Size : 4891648 (4.67 GiB 5.01 GB)
Raid Devices : 3
Total Devices : 3
Preferred Minor : 0
Persistence : Superblock is persistent
Update Time : Tue Mar 15 08:20:25 2011
State : clean
Active Devices : 3
Working Devices : 3
Failed Devices : 0
Spare Devices : 0
Layout : left-symmetric 校验规则
Chunk Size : 64K
UUID : e0d929d1:69d7aacd:5ffcdf9b:c1aaf02d
Events : 0.2
Number Major Minor RaidDevice State
0 8 17 0 active sync /dev/sdb1
1 8 33 1 active sync /dev/sdc1
2 8 49 2 active sync /dev/sdd1
如何制作文件系统¶
mount 各种各样的文件系统,loop 表示把本地文件当做文件系统来进行挂载。同时也还可以重新mount –bind 挂载点。对于物理分区有的时候会用完,添加就需要重起机器。所以也就产生了LVM. 逻辑分区。随着云计算到来,一切的虚拟化。原来的系统都是建立物理设备上的,现在都直接在逻辑设备上了。这样就具有更大的移值性,就像我们的CAS就是把逻辑拓扑与物理拓扑的隔离。LVM就在物理分区与文件系统之间又加了一层。文件系统直接建在LVM。 loop device 就是伪设备当做块设备。http://unix.stackexchange.com/questions/4535/what-is-a-loop-device-when-mounting 数据的存储系统是任何一个现代系统必不可少的一部分。它关系着系统是否高效与稳定。使用数据库要求太多,而文件系统而是最灵活的,但是效率可能没有数据高。为了结合自己的数据存储需求,产生定制的文件系统,而非通过的OS文件系统。例如版本控制的文件存储系统,以及现在云计算系统都有自己存储系统。例如Google的GFS。fuse 文件系统是在用户空间的文件系统。如何使用 。并且通过它可以把一些服务当做文件系统来使用。例如google的mail空间。以及ftp等等。
通过对gentoo对于各种概念有了更深的认识。
不同的文件系统就是硬件磁盘与逻辑存储之间的映射关系。 所谓的超级块就是与文件系统有关的。 并且存储的效率以及备份与压缩的机制。
还有在备份的时候,先碎片整理最小化,然后再copy数据,这样会加块的速度。 e4defrag ,可以用碎片的整理,同时利用 gparted可以还直接对硬盘进行拉大与拉小,关键是存放的文件不要被覆盖。
分区与格式化挂载¶
sfdisk 是分区为了逻辑设备,就像人们有了多个硬盘一样。这个是由硬盘前面的分区表来决定的。而分区表的大小决定了,你可以有多少个分区,并且在分区表建立文件系统,在linux 下有各种各样的mkfs工具来供你使用。然后加载在OS上,这里就要mount了。 对于mount 由于这个概念泛化了。你可以mount 本地硬盘,也可以远程(NFS,autofs,samba) 还以把本地文件本身当做文件系统进行访问。同时也可以用bind 来把一个目录绑到另一个目录里,来避免ln的不足.`mount –bind挂载功能,避免ln -s链接的不足 <http://blog.csdn.net/islandstar/article/details/7774121>`_ ,`mount –bind 的妙用 <http://www.cnitblog.com/gouzhuang/archive/2012/07/15/65503.html>`_
windows自带磁盘分区工具Diskpart使用介绍 分区与`格式化 <http://baike.baidu.com/view/902.htm>`_ 是两步不同的操作.格式化又分为低级,与高级,低级格式化是物理级的格式化,主要是用于划分硬盘的磁柱面、建立扇区数和选择扇区间隔比。硬盘要先低级格式化才能高级格式化,而刚出厂的硬盘已经经过了低级格式化,无须用户再进行低级格式化了。高级格式化主要是对硬盘的各个分区进行磁道的格式化,在逻辑上划分磁道。对于高级格式化,不同的操作系统有不同的格式化程序、不同的格式化结果、不同的磁道划分方法。
同时为了支持热mount,还有 https://en.wikipedia.org/wiki/GVfs, gvfs 可以在用户态加载空间,例如把ftp,smb等等把网络mount到本地。例如 gvfs-mount ‘ftp://user@www.your-server.com/folder’ 目录都在 .gvfs/ 下面。 并且其下有一堆的gvfs-ls/cat, 等等一堆的命令。
例如 curlftpfs 支持把http,ftp等mount到本地。
各个系统的共享,这样就可以减少大量的配置工作,例如的所有的工作机都直接mount同一个存储目录,这样就可以大量的login以及editor的配置,可以直接使用自己本机的编辑器配置,而运行在其他机器上。 这样的并行度就会大大很多。
mount.cifs 可以持 samba等等,使用fuse为基础的gvfs 可以挂载 ftp,http等。而sshfs可以直接mount ssh 帐号。 只需要两条命令: apt-get install sshfs, 然后把自己加入sshfs这个用户组就行了。 http://www.fwolf.com/blog/post/329
共享目录¶
- 两种办法做这个,一种用autofs, 一次用可以使用cifs-utils. 直接mount就行。
mount -t cifs -o user=xxxx,password=xxx //192.168.0.1/xxx /mnt/
- linux 访问windows 共享目录 也可以直接使用`smbclient <http://wenku.baidu.com/view/ab3e7ffc910ef12d2af9e7bb.html>`_
- autofs our builds use it on farm
#. 如果自己想用FUSE系统直接支持和种http,ftp等等在线系统。可以用 https://www.stavros.io/posts/python-fuse-filesystem/ 来实现。
apt-get install autofs
mkdir /network
auto.master
/network /etc/auto.mymounts --timeout=35 --ghost
auto.mymounts
prerelease -fstype=cifs,rw,noperm,user=devtools_tester1,pass=nvidia3d,dom=nvidia.com ://builds/prerelease
硬盘检查与修复¶
| extfs | e2fsck -y /dev/sda1 |
| HFSP | fsck.htfsplus -f -y /dev/sda1 |
| NTFS | ntfsfix -d /dev/sda1 |
| Reiserfs | reiserfsck -a -y /dev/sda1 |
- e2fsck 还有一个配置文件
etc/e2fsck.conf
修复的原理,那就是各种文件系统的,格式
Ext3日志原理 whats-the-difference-between-e2fsck-and-fsck-and-which-one-i-should-use
man¶
H 可以打开man的命令帮助文档。
HardLink and softlink¶
我们知道文件包括文件名和数据,在Linux上被分为两个部分:用户数据(user data)和元数据(metadata),用户数据主要记录文件真实内容的地方,元数据是记录文件的附加信息,比如文件大小、创建信息、所有者等信息。在Linux中的innode才是文件的唯一标示而非文件名。文件名是方便人们的记忆。
为了解决文件共享的问题,Linux 引入两种链接:硬链接和软连接。
- 若一个innode号对应于多个文件名,则成为硬链接
- 若文件用户数据块中存放的内容是另一个的路径名的指向,则该文件就是软链接。
what-is-the-difference-between-a-hard-link-and-a-symbolic-link
http://www.ibm.com/developerworks/cn/linux/l-cn-hardandsymb-links/ hardlink 一个用途那就是做备份,要比copy更加快速方便。
Easy Automated Snapshot-Style Backups with Linux and Rsync 可以快速建立一个 hourly,daily,and weekly.snapshots. 并且一个快速 rotate 机制,就是一个重命名。
rm back.3
mv back.2 back.3
mv back.1 back.2
mv back.0 back.1
rsync -a --delete source_directory/ backup.0/
对于文件系统的监控¶
文件系统的消息的类型与数量也是固定的,可以用api来得到,mount –make-rslave 等等就是控制的消息的传递。 同时也可以用 gardgem 以及系统默认的watch 的命令一样。这样的工具也特别需要例如node.js开发的时候就提供这的工具。实时更新重起 service.
分区表的格式¶
硬盘的分区格式是用signature 来区分的,如果是总是识别的不对,应该原来signature没有清除掉,或者不同的软件的默认的读写位置不对。 如何用dd来查询硬盘的头部信息直接来得到或者直接修改。
parted -l #查看分区格式
dd if=/dev/sdb skip=1 count=1 |hexdump -C #查看内容
dd if=/dev/zero count=1 seek=1 of=/dev/sdb #把内容清除为零
See also¶
- TFS taobao 分布式文件系统,TFS集群文件系统 把原数据放在文件名与路径上,采用对象存储,
- 存储领域面临六大趋势
- 什么是对象存储?OSD架构及原理 核心是将数据通路(数据读或写)和控制通路(元数据)分离,并且基于对象存储设备
- OpenStack对象存储——Swift
- 图片存储系统设计
- 学会理解并编辑fstab
Paper¶
Thinking¶
CHS 记住硬盘这一物理存储结构就知道来理解一切就都会明白了,物理结构本身三级目录。柱面 磁头,扇区。第一个磁道的扇区数一样吗。柱面与磁头决定一个磁道。 grub 的原理与硬盘的结构是相关的。并且始终记住一点那就是对于处理器来说,它能做的那就是程序在哪儿,程序指针指哪从哪开始执行。开始执行前要把需要的程序加载在内存。grub其实就是做了这样的事,BIOS把MBR放在内存中,并且处理器的跳转那里。MBR放的就是grub引导程序。然后呢,grub做了三件事,要确定系统放在哪。然后从那里把去把内核镜像加载在内存中,并设置相关的环境变量,例如root目录,以及内核在哪里。 然后把执行权交给内核。
– Main.GangweiLi - 15 Jan 2013
长路径与文件夹的作用 长路径来保证文件名的唯一性,能过长路径来保正。其实也就是字符串长与短一种映射,这一个就是能够解决集体操作。一次对多个文件进行同样的操作。也就是有一种方法可以直接对压缩文件来进行操作。如果解决了这个问题,其实也要不要这么文件夹。也就不是大的问题。更多的逻辑分块的需要。
– Main.GangweiLi - 12 Mar 2013
数据库与文件系统 本质上数据库本身也是一种文件系统。对于不同的存储对象,采用不同的机制。例如一些锁碎的类似于ERP这样数据适合于数据库这种存储系统。而大的块数据例如视频则任何于直接存储于文件系统上。例如不同的文件系统对于备份以及权限的管理是不一样的。 并且还有一个分布式文件系统的问题。还有版本控制库的文件系统。并且各种文件系统有融合之意。例如mongo,TFS,GFS等等。
– Main.GangweiLi - 12 Mar 2013
内存文件系统 为了使启动更加方便,把内核更不断不分层模块化。来使其更加通用,与复用。因为内核变化速度要比文件系统要快。
– Main.GangweiLi - 19 Apr 2013
文件属性 在查找的,排序的时候,利用文件属性会具有很大的优势,另外一个文件的属性是存储在哪里的。例如我想基于文件属性的查找排序是会很有用,在win7上是可以随时调整的,但是linux上却没有发现,如何大规模对象存储。对于图象。更是如此。例如利用find可以查找有限的文件属性。 IBM filesystem 系列 现在才对文件系统的认识有了更深的认识。需要文件系统具有什么样的能力。
文件系统中节点的类型¶
- directory
- file
- symlink
- block device
- charactor device
- FIFO
- unix domain socket
References¶
| [1] | http://www.jianshu.com/p/c6a530365bea |
Module与driver¶
linux下driver的安装还是很有挑战的,会遇到各种的不兼合,并且会无法适从。但是明白其加载原理之后,自然一切都了然于心了。
driver起的就是逻辑设备,要想到一个linux中使用一个设备,就为其建立一个逻辑设备也就是driver,正是因为这一层逻辑设备,我们才可以各种虚拟设备。以及实现虚拟化的。
这个映射关心是由udev来做实现的,而driver本身的管理是由modeprobe.conf来管理的。 module的依赖,以及alias,以及blacklist机制,还可以配制module的参数。并且还可以不用加载直接执行就可以直接执行的。每一个module,driver的管理配置都可以放在 etc/moduleprobe.d/ 下面。
例如 http://askubuntu.com/questions/112302/how-do-i-disable-the-nouveau-kernel-driver 就是利用了blacklist
并且一般情况下换了硬件之后,OS不工作了,或者工作不正常了,例如桌面进不去了换了显卡之后,只要重装一下,所有状态reset为正常值应该就好了。 例如 sudo apt-get install nvidia-331 然后 reboot .
device Management¶
这个事情起因是在这里http://www.kroah.com/linux/talks/ols_2003_udev_paper/Reprint-Kroah-Hartman-OLS2003.pdf 原因硬件命名规则太死板了,例如硬盘太多,原来那种major/minor号又不够。 因为每位都8位,并且还有很预留的,另外 是热插拔的硬件很多,总不能都事先留着吧,那样/dev的目录太大了。另外也能保证每一次都在同一个地方。这样内核就头疼了。
后边就有udev这种方法,由kernel只告诉用户有硬件来了,它叫什么名字,由你告诉我,然后再用对应的driver来读取他。 也就是为什么多个硬件可以共用一个driver,或者你可以靠一个假的硬件原因。现在有了逻辑设备。 driver与逻辑设备对应。 我可以指这个mapping,也可以系统自己生成。系统采用第一次生成后保存下来。以后延用。
mdev,udev两者实现的基理不同,udev采用 netlink的机制,自己造一个Dameo来检测 uevent,而mdev 则是注册一个回调函数来实现。 /sys/kernel/hotplug 。http://blog.csdn.net/lifengxun20121019/article/details/17403527
http://git.busybox.net/busybox/plain/docs/mdev.txt http://wiki.gentoo.org/wiki/Mdev
when you plug in a new device such as USB. which label “sdb…” will be used for it. here you can use udev. 1. db store the user device information 1. rule how to recognize the device. 当你发现你的OS在新的硬件上,不识别,例如网卡不能用了,第一步那就是先把这个rule给删除了。* rm -fr /etc/udev/rules.d/* 1. udev的实现原理 1. 使用udevadm修改usb优盘在/dev下的名字 1. Linux┊详解udev
如果你想定义硬件的命名等都是可以用 udev.rules 来解决的。 writing udev rules .
如何写查询属性可以用 udevinfo 或者 udevadm info -qury=property -path=/sys/block/sda
driver 之间的依赖关系是由LKM来管理,如何自动加载与实现逻辑设备与物理设备的mapping 主要是对应的pci数据结构,每一个硬件都会用vender,device ID,以及相对应的subID,是通过udev来实现的与管理的,这个就像windows,pnpUtils是一样的。
每一个设备成功后都会占用一个端口号或者内存地址段。应该是每一个硬件都会ID之类的东东,内核来做了这个mapping,例如eth0 对应哪 一个网口。 就像我们在NEAT所做的,逻辑设备与物理设备之间的mapping. 并这个关系更规范与通用化一些。
kernel module driver install and debug¶
kernel module usually end with xxx.ko. from linux kernel 2.6, the kernel use dynamic mechanism. you dynamically insmod,rmmod . use the depmod to generate /lib/modules/2.6.xx/modules.dep and then modprob would automatically insert the module according the modules.dep. the driver is one of module. the module could have alias name.
| Item | Content | Remark | |
|---|---|---|---|
| module location | /lib/modules/kernel version /kernel/drivers | ethernet card driver /lib/modules/2.6.4-gentoo-r4/kernel/drivers/net/r8168.ko | |
| configuration file | etc/modules.autoload.d/XX | you just need to add the module name here. etc/modules.autoload.d/kernel-2.6 | |
| modprobe | modprobe r8168.ko | the module could have alias name. etc/modprobe.d/XXXX | |
| depmod | depmod -a r8168 | ||
| dmesg | kernel会将开机信息存储在ring buffer中。您若是开机时来不及查看信息,可利用dmesg来查看。开机信息亦保存在/var/log目录中,名称为dmesg的文件里。 | dmesg用来显示内核环缓冲区(kernel-ring buffer)内容,内核将各种消息存放在这里。在系统引导时,内核将与硬件和模块初始化相关的信息填到这个缓冲区中。内核环缓冲区中的消息对于诊断系统问题 通常非常有用。在运行dmesg时,它显示大量信息。通常通过less或grep使用管道查看dmesg的输出,这样可以更容易找到待查信息。例如,如果发现硬盘性能低下,可以使用dmesg来检查它们是否运行在DMA模式: |
See also
- 解析 Linux 内核可装载模块的版本检查机制 以及 如何突破其CRC验证 简单直接把crc值,直接在elf里改成符合规定的值,说白了就是凑答案 .
- module common command 以及其`实现机制 <http://read.pudn.com/downloads37/sourcecode/unix_linux/124135/Linux%E5%86%85%E6%A0%B8%E6%A8%A1%E5%9D%97%E7%9A%84%E5%AE%9E%E7%8E%B0%E6%9C%BA%E5%88%B6.PDF>`_ .
$dmesg | grep DMA
内核检测到硬件,然后去加载mapping的driver,在加载的过程中要经过modeprobe.conf这样的过虑,并且解决其依赖关系。没有对应关系就要手工加载了。
一般是要把module放在 /lib/modules/<kernel version>/kernel/driver/net 以及去修改 /etc/modules.d/<kernel version
2.4 的版本 用的是module.conf,而2.6的版本用是modeprobe.conf
所以多个硬件可以共用一个driver,只需要用alias 把硬件本身映射到一个别名。
硬件一般用中断传递信息,而内核如何来传递这些信息用uevent, 不管你的底层是什么中断。并且uevent 通过netlink来进传送。
底层的中断又有很多¶
PCI总线的中断,例MSI与MSI-X中断机制。中断的级联扩展。
内核的调试
Linux 系统内核的调试 主要有三种kgdb,SkyEye,UML三种技术。
intel ethernet 153a 网卡不稳定¶
查看问题的,第一个要收集信息,不要轻易破坏了环境。尽可能多的收集信息 #. 保存error 信息 #. save /var/log/dmesg 与 /var/log/syslog #. 查看 是否内核加载了 cat /proc/modules |view - #. 根据error message进行初步的推理并验证 #. 提炼你的问题,一句话,几个词 #. ehtools 查看并且修改硬件。 #. insmod -m 查看插入时信息 #. 看看没有新版本可以用,看看CL. http://sourceforge.net/projects/e1000/ #. 去官网查看相关的FAQ 以及bugs. http://sourceforge.net/p/e1000/bugs/430/ #. 还有那是 READE #. 最后看一个 开发framework,去找一个init, close函数,只需要看看其做了什么,就知道了。
driver 的开发¶
一般都是register, init, shutdown, close等等几个函数接口。 http://10.19.226.116:8800/trac/ticket/2705 就是标准 .so 只是链接的库不同,以及编译的选项要与主机匹配。 http://www.tldp.org/LDP/lkmpg/2.6/html/x181.html 有详细的教程
内核的编译都需要内核的头文件,以及symbols表,以及依赖与加载的先后关系。 以及内核的版本号,如果开启了版本的匹配功能,则需要对应,不然不能加载。
内核用uevent与用户态通信。
insmod/lsmod的原理。 http://elinux.org/images/8/89/Managing_Kernel_Modules_With_kmod.pdf